
STATE.md e TASKS.md, i due file che orientano Claude nel tuo second brain (2026)
Il mio vault ha tre milioni di parole. Claude si orienta leggendone tremila. Perché ho aggiunto due file di governo, come funzionano, e i template completi nel deep dive.

Sabato mattina, la moka ancora sul fornello. Apro una sessione nuova di Claude, di quelle senza memoria, che non sanno niente di quello che ho fatto ieri. Scrivo una riga sola: “a che punto siamo”. Lui apre due file, li legge, e mi risponde con lo sprint della settimana, gli alert aperti e la task che scade domani. Tutto giusto, tutto aggiornato.
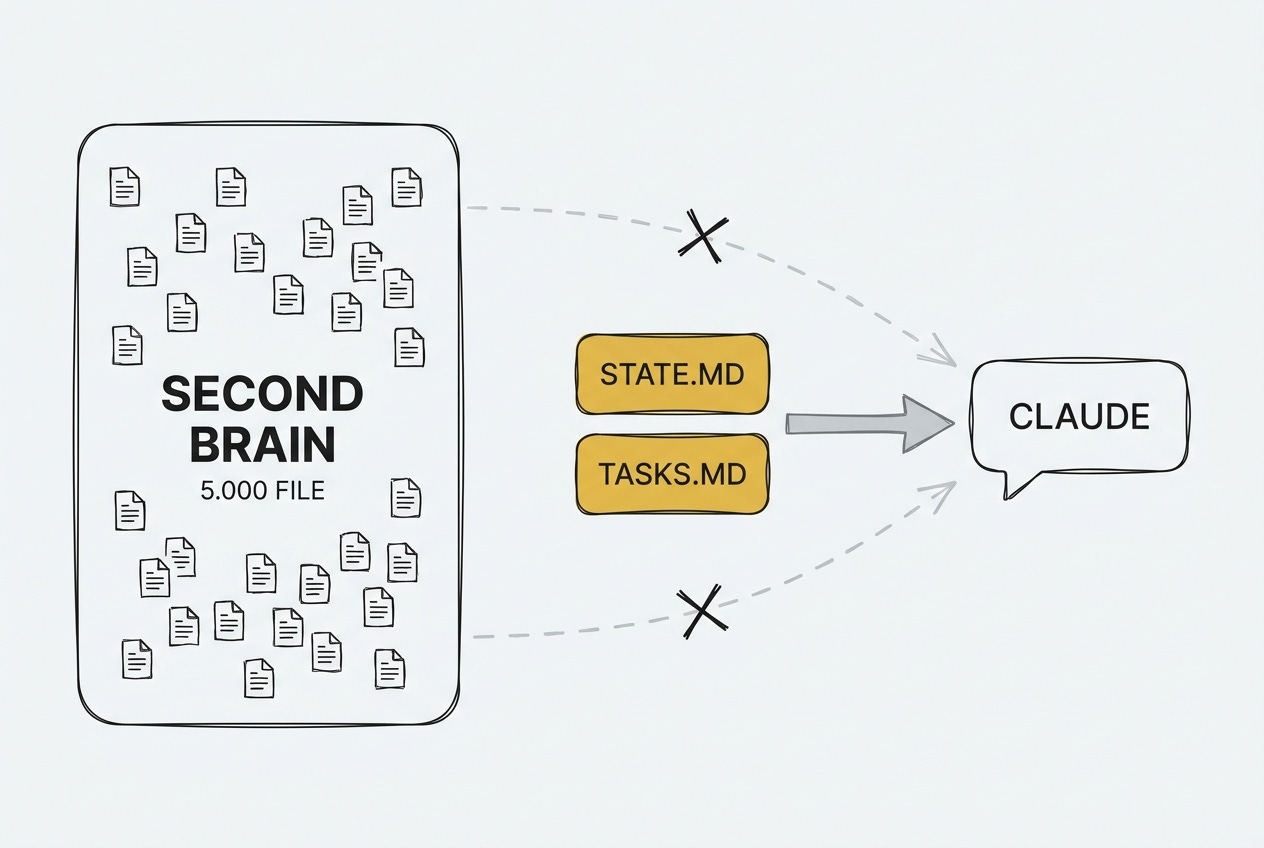
Due file. Meno di tremila parole. Dentro un second brain che di parole ne contiene più di tre milioni.
Questo post è la storia di quei due file, STATE.md e TASKS.md. Se mi leggi da un po’ conosci già i tre file che fanno funzionare un agente AI, CLAUDE.md con le regole, MEMORY.md con l’identità, log.md con la storia. Questi due non li sostituiscono e non valgono di più: sono il quarto e il quinto della stessa famiglia, e il loro mestiere specifico è tenere il contesto aggiornato e dettagliato, settimana per settimana, giorno per giorno.
In sintesi. STATE.md è la fotografia dello stato corrente del tuo second brain: decisione strategica, sprint, alert. TASKS.md è il backlog operativo: cosa è urgente ora, cosa viene dopo, cosa è stato chiuso. Un agente AI tipo Claude li legge per primi a ogni sessione e si orienta in meno di tremila parole, senza rileggere il vault intero.
Questo post è figlio della guida completa a Cowork che ho pubblicato a inizio mese: lì c’è la mappa di tutto il sistema, qui scendiamo in una stanza precisa. Se non l’hai letta, parti da lì.
Il problema, ogni sessione nuova ricominciava da zero
Ti racconto dove ero a inizio maggio, perché se hai un second brain che cresce ci arriverai anche tu.
Il mio vault oggi conta quasi cinquemila file markdown. Clienti, progetti, decisioni, log, strategie, bozze. Tre milioni e duecentomila parole, le ho contate. Ed era tutto in ordine: cartelle PARA, note che si linkano, niente caos. Il problema non era l’ordine. Il problema era che un modello AI, davanti a tutto quell’ordine, non sa da dove cominciare.
Perché c’è un fatto tecnico che dimenticano tutti nei tutorial sul second brain: la finestra di contesto di un modello è finita. Claude arriva a gestire fino a un milione di token, che letti così sembrano infiniti. Il mio vault, convertito in token, ne occupa più di quattro volte tanto. Non ci sta. E c’è il dettaglio che conta ancora di più: la finestra non conviene nemmeno riempirla, perché già intorno al 70% di riempimento l’output comincia a degradare. Più contesto inutile dai al modello, più diluisci quello che conta, e le risposte peggiorano invece di migliorare.
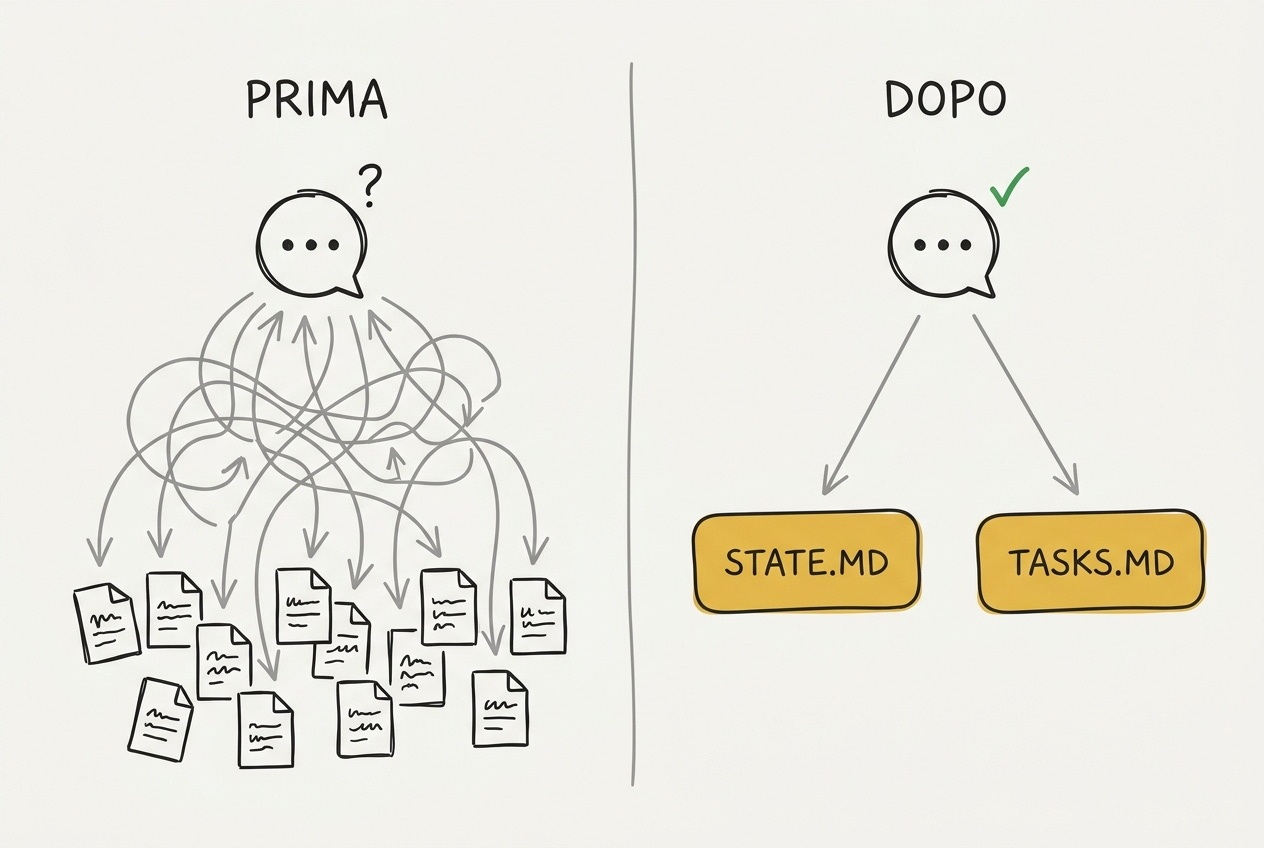
Quindi ogni sessione nuova faceva la stessa scena. Claude apriva l’indice, poi la memoria generale, poi un log, poi un altro log, e dopo qualche minuto di esplorazione mi chiedeva conferma di cose che nel vault erano già scritte. Ogni chat ripartiva da zero, come un collaboratore nuovo al primo giorno, ogni giorno. I token se ne andavano in orientamento invece che in lavoro. E io pagavo due volte: in attesa e in qualità.
La cosa che mi ha fatto scattare la decisione è stata accorgermi che stavo rispiegando a Claude lo stato dei miei clienti per la quarta volta in una settimana. Quando rispieghi la stessa cosa quattro volte, il problema non è il modello. È che manca un sistema.
Il principio, la memoria ha tre velocità
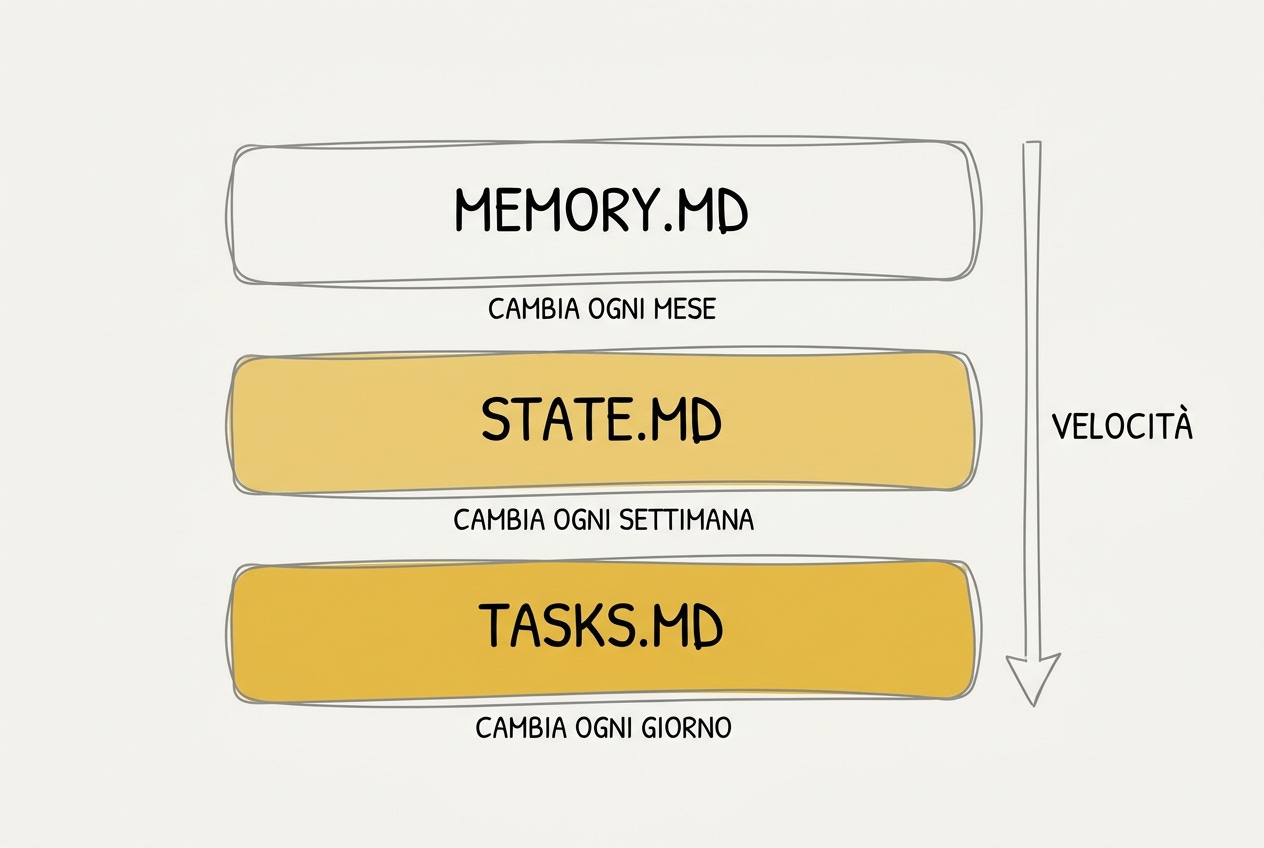
La soluzione l’ho costruita partendo da un’osservazione semplice: non tutta la conoscenza di un second brain invecchia alla stessa velocità.
C’è la conoscenza stabile. Chi sono, come lavoro, chi sono i miei clienti, le regole del vault. Cambia ogni mese, forse. Nel mio sistema vive in MEMORY.md, e di quella ho già scritto: è uno dei tre file del PDF che regalo ai nuovi iscritti.
Poi c’è lo stato. Qual è la priorità di questo trimestre, a che punto è lo sprint di questa settimana, quali allarmi sono accesi. Cambia ogni settimana. E prima non viveva da nessuna parte: era spalmato nei log, nelle chat vecchie e nella mia testa.
Poi c’è l’azione. Cosa devo fare oggi, cosa può aspettare, cosa ho chiuso ieri. Cambia ogni giorno.
Tre velocità diverse. E se metti informazioni a tre velocità nello stesso file, succede quello che succedeva a me: per trovare la cosa che cambia ogni giorno, il modello rilegge anche tutto quello che non cambia mai. Il sistema PARA che uso per le cartelle l’ho raccontato in [Claude + Obsidian + PARA](URL post 27/4): quella è la libreria, ed è perfetta per archiviare. Ma una libreria non ti dice a che pagina eri rimasto. Serviva un livello sopra.
Così ho aggiunto due file alla radice del vault, uno per velocità mancante.
STATE.md è la fotografia del presente. Risponde alla domanda “dove siamo adesso”. Dentro ci sono cinque cose, sempre le stesse: la decisione strategica corrente, lo snapshot delle aree di lavoro, lo sprint della settimana, le lezioni più importanti che ho imparato, gli alert attivi. Non è un diario: si sovrascrive. La versione vecchia non interessa a nessuno, per la storia ci sono i log.
TASKS.md è il backlog operativo. Risponde alla domanda “cosa devo fare”. Quattro sezioni: Now, le cose dello sprint corrente. Next, le prossime settimane. Later, il trimestre e oltre. Done, quello che ho chiuso negli ultimi sette giorni, poi si cancella e la storia resta nei log.
E poi c’è la regola che tiene insieme tutto, la più importante: questi due file sono always-load. Qualsiasi sessione, mia o di un agente, li legge prima di fare qualsiasi cosa. Sempre. È scritto nelle istruzioni del vault. Due letture, e il modello sa dove siamo e cosa serve. Solo dopo, se la richiesta lo richiede, scende in profondità nelle cartelle giuste.
Cos’è STATE.md, la fotografia del presente
STATE.md è un file markdown che vive alla radice del second brain e contiene lo stato corrente del sistema: la decisione strategica in vigore, lo sprint della settimana, gli allarmi aperti. Un agente AI lo legge a inizio sessione e sa dove si trova, senza esplorare il resto del vault.
Ti faccio vedere come è fatto il mio, anonimizzando quello che va anonimizzato.
In testa c’è la decisione master corrente: la priorità strategica che ho scelto e l’ordine delle cose. Una decisione presa una volta, scritta una volta, che ogni sessione rispetta senza che io la ripeta. Quando a fine maggio ho cambiato priorità tra i miei progetti, l’ho cambiata lì, una riga, e da quel momento ogni chat ragionava con la testa nuova.
Poi lo snapshot delle aree: una tabella corta, un’area per riga, status e focus corrente. La mia agenzia, il laboratorio AI, il personal brand, il personale. Quattro righe.
Poi lo sprint corrente: la settimana in corso, cosa è partito, cosa è in attesa, cosa è arrivato. È la sezione che cambia di più e quella che vale di più: è la differenza tra un assistente che sa cosa è successo e uno a cui devi fare il riassunto a voce.
Poi le lezioni top: le dieci cose più care che ho imparato, distillate in una riga ciascuna. Tipo che un lead silenzioso da quattordici giorni va archiviato senza pietà, o che i dati di fatturato dichiarati a memoria divergono sempre da quelli del conto. Sono lì perché il modello le applichi, non perché io le rilegga.
E infine gli alert: i rischi accesi adesso. Nel mio, oggi, c’è un cliente importante in pausa per cause di forza maggiore, con l’impatto sul fatturato ricorrente scritto in chiaro. E c’è il fatto che tre clienti pesano i tre quarti del ricavo mensile dell’agenzia, che è un rischio di concentrazione che ogni nuova decisione commerciale deve tenere a mente. Quando è scoppiato il caso del cliente in pausa, l’ho scritto una volta nell’alert: da lì in poi ogni sessione, anche quelle aperte dai miei soci, lo sapeva. Nessun passaggio di consegne, nessun “ah ma non te l’avevo detto”.
Il mio STATE.md è lungo milleottocento parole. Tutto qui. È il file più denso del vault e probabilmente il più letto.
Cos’è TASKS.md, il backlog che l’AI legge prima di lavorare
TASKS.md è il secondo file, e funziona da unica fonte di verità per le cose da fare. Quattro sezioni in ordine di urgenza, e ogni task scritta in un modo preciso: non solo il titolo, ma il perché esiste e che risultato deve produrre.
Questa è una task vera del mio file di questa settimana, leggermente ripulita:
- [ ] T4, Consolidare fatturato YTD 2026 per monitor target annuale · scadenza 7/6
- Why: la review mensile è fatta, ma senza il dato da inizio anno
il target resta non monitorabile
- Esito atteso: riga YTD vs target dentro la memoria finanzaIl “why” e l’”esito atteso” non sono burocrazia. Sono lì per il modello: una task con il perché dentro è una task che un agente può portare avanti da solo senza farmi domande a cui ho già risposto. E quando una task è chiusa, va in Done, ci resta sette giorni perché le sessioni della settimana la vedano, e poi sparisce. La storia completa vive nei log delle cartelle, non nel backlog. Un backlog che accumula storia diventa un archivio, e un archivio che si finge backlog è il modo più veloce per smettere di guardarlo.
C’è un’ultima regola che ho aggiunto da poco, dopo essermi accorto che certi task giravano nella sezione Now per giorni senza che succedesse niente: se una task sta in Now da tre giorni, scatta una decisione forzata. O la chiudo entro ventiquattro ore, o la sposto giù. Niente terza via. Il sistema me lo segnala da solo con un piccolo flag, ed è una delle automazioni più stupide e più utili che ho.
Come li ho costruiti, passo passo
Adesso la parte pratica, perché questi due file li puoi creare oggi pomeriggio. Non serve codice, non serve nessun tool particolare: serve un editor di markdown e mezz’ora di onestà su come stanno le cose.
Il primo passo è creare STATE.md alla radice del tuo vault, o della cartella dove lavori con l’AI. Cinque sezioni, quelle che hai visto sopra: decisione corrente, snapshot delle aree, sprint della settimana, lezioni, alert. La prima compilazione è la più faticosa perché ti obbliga a rispondere a domande che di solito rimandi: qual è davvero la priorità adesso? quali rischi sono accesi? Scrivilo come lo diresti a un socio che torna da un mese di ferie.
Il secondo passo è TASKS.md, stessa posizione. Quattro sezioni: Now con le cose di questa settimana, e tienile poche, tre o cinque, non quindici. Next col mese. Later col trimestre. Done vuota, si riempie da sola. Ogni task con il suo why e il suo esito atteso.
Il terzo passo è la regola di carico, ed è quello che trasforma due file in un sistema. Nelle istruzioni che il tuo agente legge sempre (in Cowork è il CLAUDE.md della cartella, ma il principio vale ovunque) scrivi che STATE.md e TASKS.md vanno letti prima di qualsiasi operazione, e che l’orientamento deve costare al massimo quelle due letture. Io l’ho scritta così, e da quel momento ogni sessione parte già calda.
Il quarto passo sono le cadenze, perché un file di stato non aggiornato è peggio di nessun file: mente con autorevolezza. La mia regola è semplice: STATE.md si aggiorna la domenica, al check-in settimanale, e ogni volta che cambia una decisione importante. TASKS.md si tocca quando le priorità cambiano, anche tutti i giorni. La domenica sono dieci minuti, non di più, perché stai sovrascrivendo una fotografia, non scrivendo un report.
Il quinto passo arriva solo quando il sistema cresce, e te lo dico per completezza: i file di stato si possono moltiplicare per livello. Nel mio vault oggi ci sono quattordici STATE.md e sedici TASKS.md: uno alla radice, uno per area di lavoro, uno per ogni cliente importante. Quello alla radice tiene solo le cose trasversali, quelli di area tengono la loro parte di mondo. Ma questo è il passo cinque, non il passo uno. Se il tuo vault ha cento file, il root basta e avanza.
In fondo al post, prima del paywall che arriva tra qualche giorno, trovi il prompt completo che puoi dare a Claude per generare la prima versione dei due file leggendo il vault che hai già.
Il caso, orientarsi in tremila parole dentro tre milioni
Ti do i numeri veri, misurati sul mio vault sabato mattina, perché senza numeri questo resta un discorso di filosofia della produttività.
Il vault: 4.964 file markdown, 3.218.798 parole. Il mio STATE.md di root: 1.822 parole. Il TASKS.md: 908. Totale dell’orientamento: 2.730 parole, circa tremilacinquecento token. Vuol dire che una sessione nuova si orienta consumando una frazione minuscola della finestra, lontana anni luce da quel settanta per cento oltre il quale la qualità cala, e tutto il resto rimane libero per il lavoro vero.
Prima di questi due file, l’orientamento passava da tre letture diverse, l’indice, la memoria generale, le regole operative, e dopo quelle tre letture il modello sapeva chi ero ma non sapeva ancora dove eravamo: lo stato della settimana stava sparso nei log, e per ricostruirlo doveva aprirne due o tre, col rischio di pescare quello vecchio. Adesso la sequenza è: due file, poi dritto al lavoro.
Ma il risparmio di token, te lo dico onestamente, è il beneficio minore. Il beneficio maggiore è la qualità delle risposte. Un modello che parte da un contesto piccolo, denso e aggiornato sbaglia meno di uno che parte da un contesto grande, diluito e di cui non sa cosa è ancora valido. Quando ho chiesto a Claude di valutare un preventivo nuovo, la risposta ha tenuto conto da sola del rischio di concentrazione scritto nell’alert. Non gliel’ho ricordato io. L’ha letto, perché stava nel posto dove legge sempre.
E c’è il beneficio che non avevo previsto: i due file funzionano anche per gli umani. Quando torno da tre giorni fuori, la domenica sera, leggo il mio stesso STATE.md e mi rimetto in carreggiata in cinque minuti. Il file che avevo scritto per l’AI è diventato il modo in cui io stesso rientro nel mio lavoro.
Gli errori che ho fatto, così non li fai tu
Quattro errori, tutti miei, tutti già pagati.
Il primo: all’inizio STATE.md mi è cresciuto in mano come un secondo MEMORY.md. Ci finiva l’identità, la storia, il contesto dei clienti, tutto. Sbagliato. La regola che mi ha salvato è brutale: ogni informazione vive in un solo file, gli altri al massimo la linkano. Se un fatto sta sia in STATE che in MEMORY, è un bug, e prima o poi le due versioni divergono e il modello pesca quella sbagliata. STATE tiene solo quello che cambia ogni settimana.
Il secondo: trattarlo come un diario. Le prime settimane aggiungevo righe sotto le righe vecchie, e il file si allungava invece di restare una fotografia. Un file di stato si sovrascrive. Fa male le prime volte, sembra di buttare via lavoro, poi capisci che la storia non è persa: sta nei log, che esistono apposta.
Il terzo: il backlog che non si svuota. Task chiuse che restavano in Done per settimane, task aperte che galleggiavano in Now senza decisione. Un backlog sporco è un backlog che il modello smette di rispettare, perché impara che metà delle cose scritte lì non contano. Da qui le due regole: Done si pulisce dopo sette giorni, e la task ferma in Now da tre giorni esige una scelta.
Il quarto, il più subdolo: aggiornare “quando mi ricordo”. Ho avuto un periodo in cui lo snapshot girava vecchio di dieci giorni, e me ne sono accorto solo quando le risposte hanno cominciato a basarsi su uno stato superato. Per questo la cadenza è fissa, la domenica, agganciata a un rito che esiste già. Un file di stato è buono quanto la sua data di aggiornamento, e infatti la data sta scritta in cima al file, la prima cosa che si vede.
Da qui in poi entriamo nella parte operativa pura: i template completi di STATE.md e TASKS.md, sezione per sezione con i commenti su come compilarli, le regole di aggiornamento e come adattarli se lavori da solo o con un team. È la parte che tengo per chi sostiene questo lavoro. Resta aperta a tutti ancora per pochi giorni, poi chiude dietro il paywall, quindi se la vuoi leggere intera fallo adesso.
Deep dive, i template completi di STATE.md e TASKS.md
Quello che hai letto fin qui è il perché e il come ad alto livello. Questa parte è il copia-incolla: i due template che uso davvero, commentati riga per riga, più le regole per tenerli vivi. L’obiettivo è che stasera i due file esistano nel tuo vault.
